CAPACOA, La Culture Crée et nos partenaires ont terminé la phase 2 de l’initiative Un avenir numérique lié. Ce billet offre un aperçu de nos principales activités et des enseignements tirés. On trouvera des liens aux rapports complets à la fin de ce billet.
Le déchiffrement des concepts progresse
Vous est-il déjà arrivé de vous retrouver au beau milieu d’une discussion et de constater que vous ne discutez pas de la même chose, mais de deux choses bien différentes? Que vous utilisez le même mot, mais celui-ci n’a pas le même sens pour vous et votre interlocuteur?
Cela s’est produit à plusieurs reprises au cours de la phase 2 de l’initiative Un avenir numérique lié, la période des activités de modélisation de Wikidata. L’ambiguïté des mots est traitresse. Un seul mot peut avoir plusieurs sens (polysémie) et différents mots peuvent désigner la même chose ou le même concept (synonymie). En anglais, conductor par exemple, peut être une profession, un poste dans une organisation ou un rôle dans une production. Or, les trois sens sont possibles. Pour représenter ce concept lié au travail sous la forme de triplet RDF (sujet-prédicat-objet), des propriétés distinctes peuvent servir de prédicat pour désigner la profession, le poste et le rôle.
Au cours de l’année dernière, nous avons travaillé avec le Conseil québécois du théâtre, La Culture Crée et d’autres organismes pour définir de bonnes pratiques pour représenter les informations sur les arts de la scène sous forme de données ouvertes liées. Cela nous a obligés à nous détacher des mots afin de nous concentrer sur les concepts simples de haut niveau qu’ils représentent. Ensuite, nous avons décrit ces concepts de manière précise en faisant abstraction du domaine afin qu’ils aient la même signification, peu importe la langue ou le domaine. Dans un cas, par exemple, nous avons emprunté le concept de « groupe » à l’ontologie CIDOC-CRM pour représenter tous les groupes, ensembles, troupes et organisations des arts du spectacle, quelle que soit leur forme juridique (voir l’article Wikidata qui en résulte et la discussion).
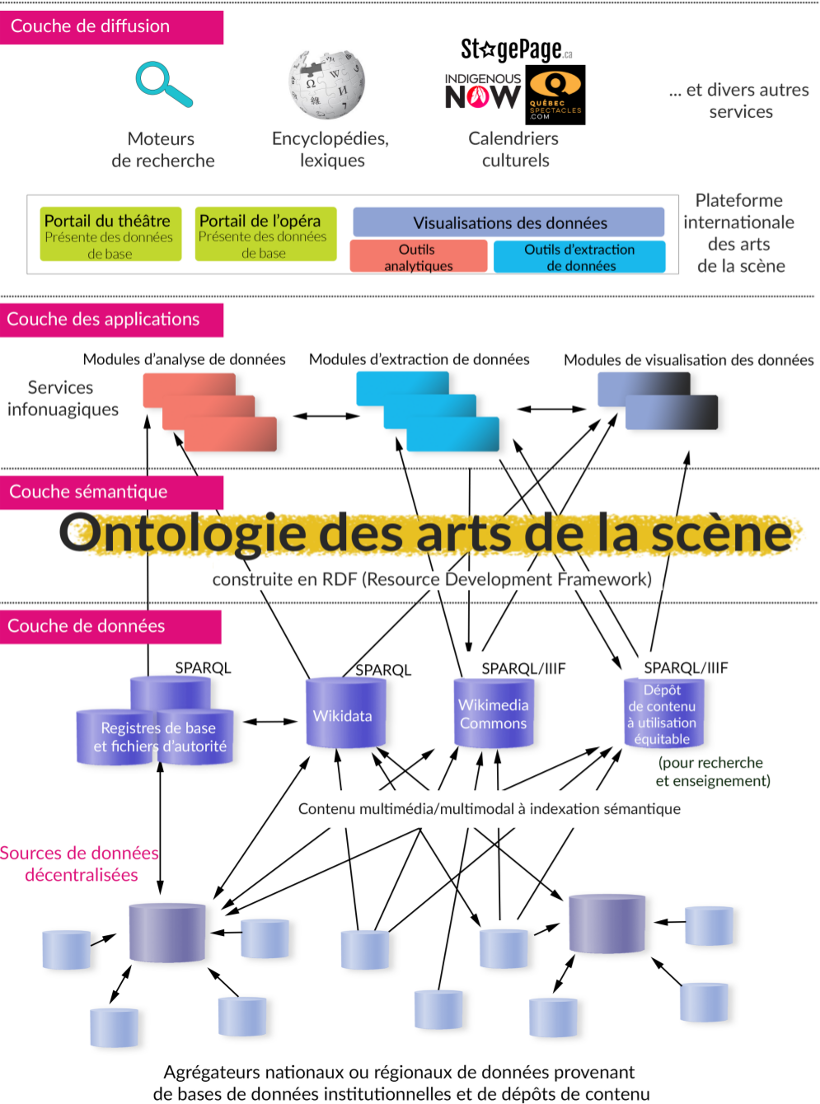
À la fin de la phase 2, nous avions réalisé des progrès significatifs vers une ontologie harmonisée des arts du spectacle — la couche sémantique de la vision d’un écosystème de données ouvertes liées pour les arts de la scène. Ces progrès ont été documentés dans le WikiProject Performing arts et dans la documentation Artsdata.ca. Mais il reste encore beaucoup à faire. Les efforts de modélisation se poursuivent en collaboration avec le Performing Arts Information Representation Community Group et la communauté LODEPA (Linked Open Data Ecosystem for the Performing Arts).
Le Resource Description Framework (RDF) est un ensemble de spécifications du W3C permettant de représenter des informations sur le Web. Le triplet RDF est la composante fondamentale de l’ensemble de la toile de données ouvertes liées.
Le modèle de référence conceptuel (CRM) de CIDOC est une ontologie RDF classique développée par le secteur du patrimoine culturel. L’alignement sur le CIDOC-CRM permet de réutiliser les informations dans tous les secteurs culturels.
Une masse critique d’entités nommées a été constituée
Il faut également déchiffrer les concepts derrière les entités nommées.
Par exemple, un enregistrement d’une base de données décrit-il une organisation ou un lieu? Ou les deux?
Pour le gestionnaire de la base de données, cette différence peut être sans importance. Cependant, lorsque vient le moment de synchroniser différents ensembles de données, l’ambiguïté devient une boîte de Pandore et une source de maux de tête.
Au cours de la dernière année, nous avons entrepris, avec La Culture Crée, LaCogency, le Conseil québécois du théâtre et d’autres partenaires, d’intégrer des entités nommées de personnes, d’organismes, de bâtiments et de lieux dans Artsdata.ca et Wikidata. Ces entités nommées font partie de la couche de données dans notre vision des données ouvertes liées. Elles constituent une base pour l’écosystème de données et sont une condition préalable à la réutilisation des informations sur les arts de la scène.
Une entité nommée est une « chose » avec un nom en langage humain servant à distinguer cette chose des autres choses du même type. Les personnes, les organisations et les œuvres sont des exemples d’entités nommées. Dans les fichiers d’autorité, ce nom sera associé à un identifiant unique pérenne. Dans les données liées, cet identificateur et ce localisateur sont appelés des identificateurs de ressources uniformes (ou URI).
Ce fondement est-il déjà en place? Grâce à un nouveau prototype de logiciel de reconnaissance des entités nommées (NER), le nombre de personnes, d’organisations et de lieux dans Artsdata a été décuplé, passant de 1 040 à 11 100!
Selon les données de référence de Statistique Canada, nous avons saisi environ la moitié des entités nommées pour les personnes et les lieux et environ 20 % de celles des organisations (voir les estimations dans cette présentation).
Des efforts supplémentaires seront déployés en 2021-2022 pour atteindre les associations et les syndicats qui détiennent des ensembles de données sur les personnes et les organisations. Si vous avez des ensembles de données à contribuer à Wikidata et à Artstdata, veuillez contacter Bridget MacIntosh à ldf.anl@capacoa.ca.
Nous continuerons également à démêler les enregistrements qui confondent les informations sur le lieu et l’organisation… avec beaucoup de patience — et de Tylenol.
La collecte de données sur les événements s’accélère
L’une des validations de principe de l’ANL consiste à assembler des entités nommées dans des entrées de calendrier d’événements riches, avec des informations complètes sur la distribution et des détails sur les organisateurs. Nous avons donc intensifié nos efforts pour renforcer les capacités de moissonnage d’informations sur les événements à partir de sites Web. En plus de la technologie Footlight, La Culture Crée a commencé à « glaner » des données structurées Schema partout où elles étaient disponibles. Elle a également commencé à expérimenter un nouvel outil appelé Capacitor pour faire évoluer la technologie de moissonnage d’informations. Toutes ces technologies se sont avérées efficaces : le nombre d’événements dans Artsdata a augmenté de 400 %, passant de 1 140 à 4 620, alors qu’il s’agissait d’une année de pandémie.
Or, il pourrait y avoir jusqu’à 75 000 événements d’arts de la scène par an au Canada. C’est beaucoup d’informations à codifier en données et à charger dans Artsdata. Les outils alimentés par l’IA peuvent faire le gros du travail. Pourtant, nous avons besoin d’autres stratégies de production de données pour atteindre l’exhaustivité et la qualité des données. Nous avons besoin de contributions supplémentaires provenant directement de la communauté des arts de la scène elle-même. La technologie ne peut pas tout faire. Ça va prendre la collaboration active du milieu.
Ce n’est qu’à cette condition que nous pourrons offrir des réponses cohérentes, de qualité et opportunes à la question la plus importante : « Quels spectacles y a-t-il ce soir près d’ici? »
Rapports et évaluations
Nous avons accompli tellement de choses l’année dernière qu’il est impossible de rendre justice aux efforts de tous les membres de l’équipe ANL dans un seul billet de blogue. Entre l’incroyable travail de LaCogency et du Conseil québécois du théâtre autour de Wikidata, les ateliers de la communauté LODEPA et les centaines d’heures d’encadrement de nos navigateurs numériques, nous avons beaucoup à célébrer. Voici donc des rapports détaillés sur l’ANL et ses différentes composantes.
Mis-à-jour le 8 août 2021



Leave a Reply
Want to join the discussion?Feel free to contribute!