
If you have been reading the Linked Digital Future report or any other literature about digital discoverability, you may have stumbled upon the term “knowledge graph” and wondered what on earth it can be.
Even experts disagree as to what a “knowledge graph” actually is. In simple terms, one could say that a knowledge graph is the combination of two things:
- A data model (a conceptual model for representing information as data, with formal ontologies providing a set of rules about how knowledge must be organized within a given knowledge domain); and,
- The actual data, stored in a graph database.
This ‘simple’ definition involves a fair deal of technical jargon. More than one could explain over a single post. So let’s focus on the second part of it: “data, stored in a graph database”.
So, what is a graph database?
According to Wikipedia, “a graph database is a database that uses graph structures for semantic [i.e., meaningful] queries with nodes [i.e., data unit], edges [i.e., relationships or links], and properties to represent and store data.”
There is a lot to unpack in this definition, but the most important aspect to understand is the edges – or the relationships – that connect data units to one another. Graph databases hold the relationships between data as a priority. Without relationships, there can be no graph database, no linked data and no knowledge graph.
Here’s an example:
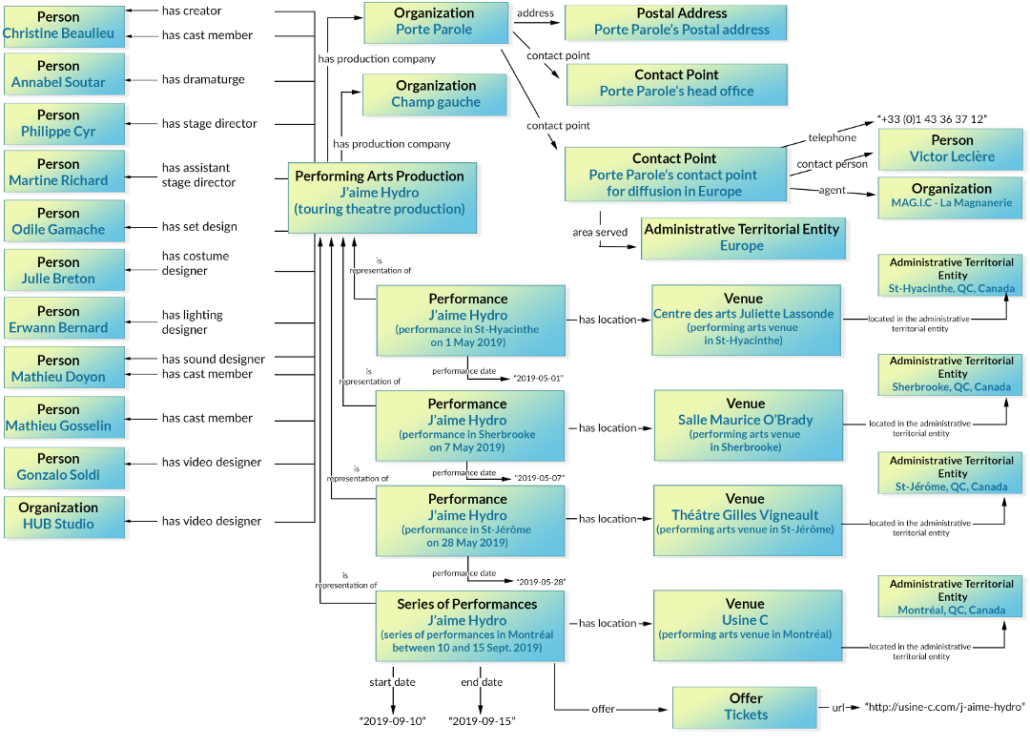
— Christine Beaulieu is a cast member in “J’aime Hydro”.
If this sentence were a graph, Christine Beaulieu and the documentary theatre production J’aime hydro would be two nodes. And “is cast member in” would be their edge or relationship.
Let’s remove that relationship from the sentence. We are left with:
— Christine Beaulieu. J’aime Hydro.
The two nodes still exist. However, without their relationship, they are just sentence fragments that no longer carry any meaning.
Now, we could change that relationship to “is creator of” and we would end up with a different meaning associated with the same two nodes. These two nodes can also have many other connections with other nodes. For this reason, graph databases resemble very much social networks. Social networks can be multifaceted and intertwined: the same person can be a colleague to several co-workers, a parent to three children, and a friend to other people. In the same fashion, J’aime hydro can be multiple things to different people: a creation project for a theatre company, a work contract for an actor, a touring show for a presenting organization, and a live performance for a theatre-goer.
To simplify all of the above, one could say that the knowledge graph and the graph database are about relationships and meaning. Very much like social networks. Or the performing arts value chain.
But why is any of this important for the arts sector?
A graph database is fundamentally different from a traditional relational database. Their structures are different. They enable different ways of using and sharing data. And they can lead to different ways of thinking about data.
Let’s have a comparative look at the relational database and the graph database.

As the above table illustrates, relational databases and graph databases are not only fundamentally different in the way they organize data; they enable very different digital possibilities. And they can lead to different digital mindsets.
One is about sorting things in buckets. The other is about valuing relationships between things.
My bet is that the latter is more apt at generating the kind of radical collaboration that the arts sector needs to fully realize its digital transformation.
The author thanks Gregory Saumier-Finch, CTO at Culture Creates, and Jai Djwa, Principal at Agentic Communications, for their contributions to this post.
Recommended readings
MT Buzzer, Graph database vs. relational database, July 26, 2018.
Favio Vázquez, Graph Databases. What’s the Big Deal?, January 22, 2019.
Stefan Summesberger and Juan Sequeda, Knowledge Graphs Need Social-Technical Solutions, May 24, 2019.
Josée Plamondon, Web sémantique : de choc culturel à transformation numérique, 16 juillet 2018.
Josée Plamondon, Produire des données : entre outils de marketing et bases de connaissances, 21 août 2019.
 CC 4.0 BY-SA
CC 4.0 BY-SA 
 CC BY 4.0
CC BY 4.0  CC BY-SA 4.0
CC BY-SA 4.0  CC BY 4.0
CC BY 4.0 






Excellent introduction to Knowledge Graphs!
There has been a steady rise of interest around Knowledge Graphs over the past couple of years, and for good reason. Below is a supporting quote from The World Wide Web Consortium (W3C). Who is the W3C? W3C is an international community that develops open standards to ensure the long-term growth of the Web.
——————————————-
From https://www.w3.org/2013/data/
Traditional approaches to data have focused on tabular databases (SQL/RDBMS), Comma Separated Value (CSV) files, and data embedded in PDF documents and spreadsheets.
We’re now in midst of a major shift to graph data with nodes and labelled directed links between them.
Graph data is:
◼ Faster than using SQL and associated JOIN operations
◼ Better suited to integrating data from heterogeneous sources
◼ Better suited to situations where the data model is evolving
What impressed me most is that the article presents knowledge graphs as representations of meaning rather than collections of data. By connecting entities through semantic relationships, information becomes understandable not only to humans but also to intelligent systems that require contextual reasoning